Assistive agents performing household tasks such as making the bed, preparing coffee, or cooking breakfast, often consider one task at a time by computing a plan of actions that accomplishes this task. The agents can be more efficient by anticipating upcoming tasks, and computing and executing an action sequence that jointly achieves these tasks. State of the art methods for task anticipating use data-driven deep network architectures and Large Language Models (LLMs) for task estimation but they do so at the level of high-level tasks and/or require a large number of training examples. Our framework leverages the generic knowledge of LLMs through a small number of prompts to perform high-level task anticipation, using the anticipated tasks as joint goals in a classical planning system to compute a sequence of finer-granularity actions that jointly achieve these goals. We ground and evaluate our framework's capabilities in realistic simulated scenarios in the VirtualHome environment and demonstrate a 31% reduction in the execution time in comparison with a system that does not consider upcoming tasks.
Household Domain
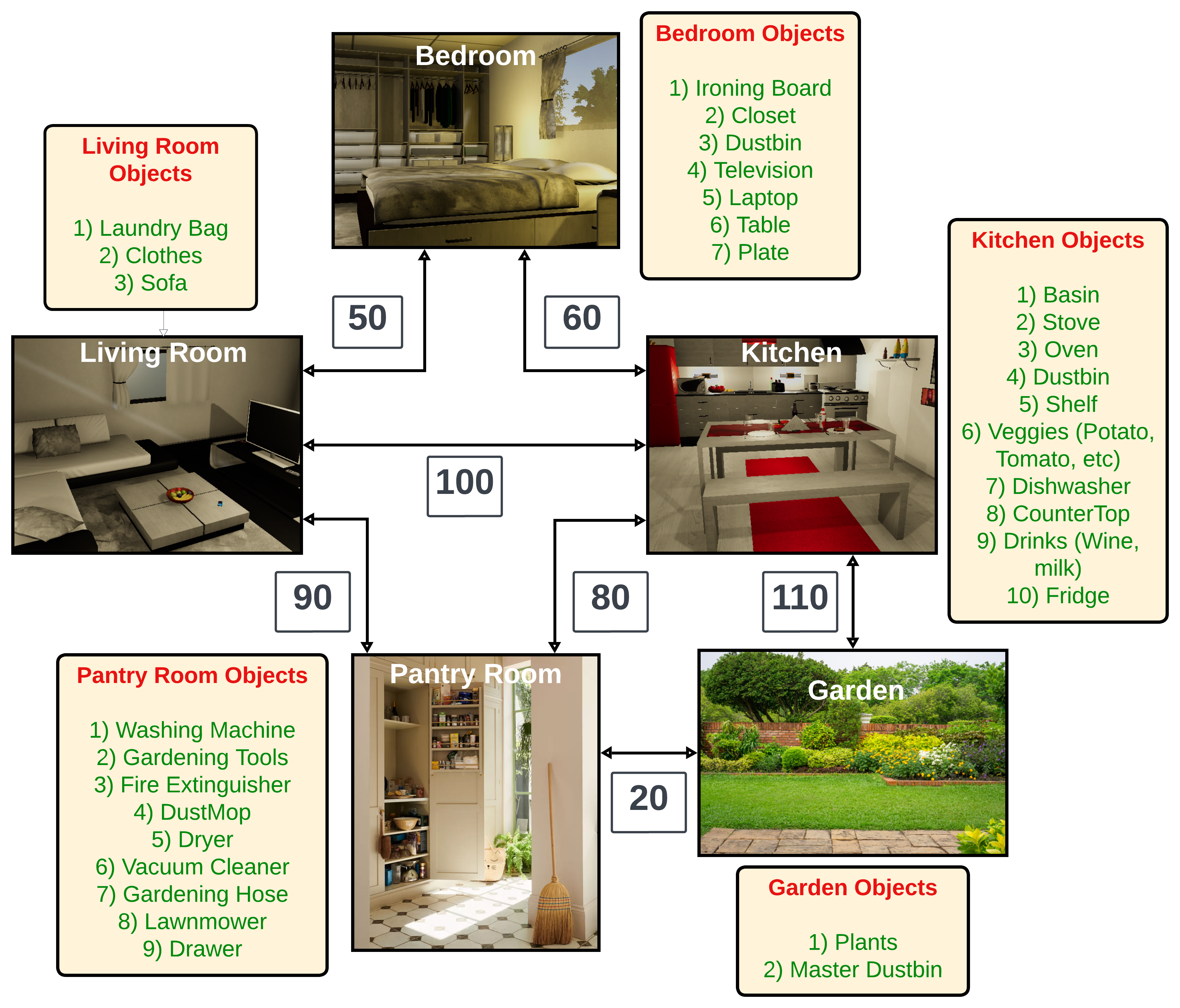
We create a household domain in PDDL where an agent has to plan a sequence of finer-granularity actions corresponding to different household tasks like doing laundry, cooking, etc. This domain consists of 33 independent actions, 5 different rooms, 33 objects distributed over 5-10 types, and 19 receptacles. A pictorial representation of the domain is shown below. Since most common household tasks involve multiple finer-granularity actions, this domain is much more useful for evaluating the performance of our framework than the domains used in previous works. This domain can be further expanded to include more rooms and complexity for more realistic evaluation.